Implementing a novel scFM tokenizer#
Beyond benchmarking existing tokenizers, Heimdall also enables users to introduce, evaluate and share novel tokenizer designs. Here, we demonstrate several examples of this. As in the first demo, we use a subset of the scTab dataset for evaluation.
import hydra
import Heimdall
from matplotlib import pyplot as plt
import matplotlib
import seaborn as sns
import scanpy as sc
plt.rcParams['pdf.fonttype'] = 42
plt.rcParams['svg.fonttype'] = 'none'
sc.set_figure_params(figsize=(6, 6), frameon=False)
sns.set_theme(style="white")
We are interested in implementing various popular tokenizers for single-cell foundation models within a standardized framework, which enables us to isolate the impact of the tokenizer itself on downstream performance.
Recap: Heimdall modularizes scFM tokenizers#
The key to Heimdall’s modularity is the compartmentalization of the tokenizer into \(F_\textbf{G}\), \(F_\textbf{E}\) and \(F_\textbf{C}\) components. Thus, to implement a novel
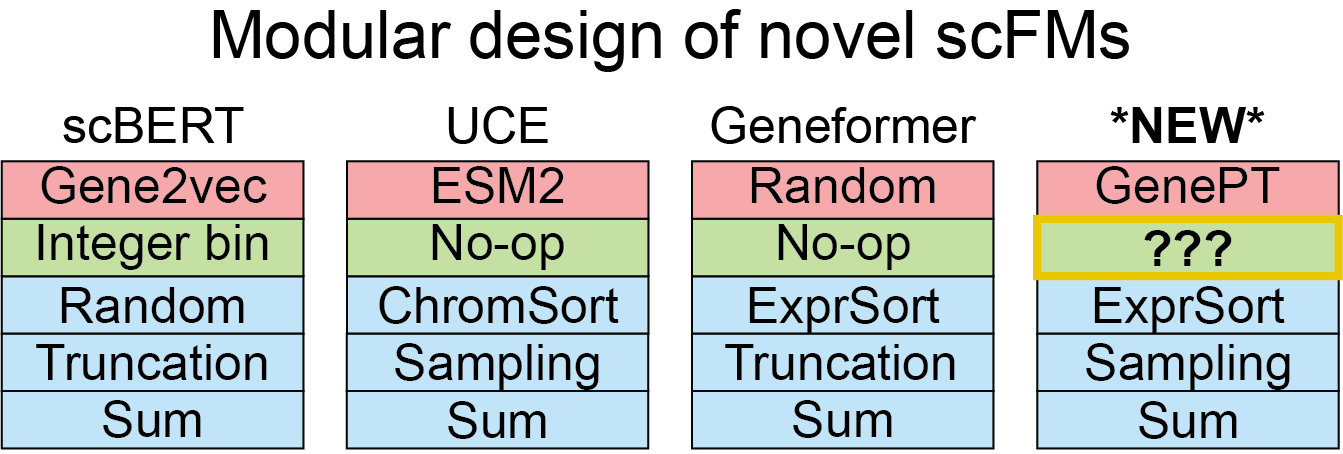
Implementing a new \(F_\textbf{G}\)#
In our experiments, we use HyenaDNA to create a novel gene-identity encoding module. In particular, we feed the DNA sequence of the gene to the HyenaDNA model, and save the outputs as a Torch Tensor file. We already provide a base class that loads the gene embeddings from a .pt file, so the implementation is straightforward after we have extracted the embeddings.
Python code#
from Heimdall.fg import PretrainedFg
class TorchTensorFg(PretrainedFg): # This is actually already provided in `Heimdall.fg`
"""Mapping of gene names to pretrained embeddings stored as PyTorch
tensors."""
def load_embeddings(self):
raw_gene_embedding_map = torch.load(self.embedding_filepath, weights_only=True)
raw_gene_embedding_map = {
gene_name: embedding.detach().cpu().numpy() for gene_name, embedding in raw_gene_embedding_map.items()
}
return raw_gene_embedding_map
class HyenaDNAFg(TorchTensorFg):
"""Mapping of gene names to pretrained HyenaDNA embeddings."""
fg/hyenadna.yaml config#
The final step is to write a config file for this \(F_\textbf{G}\)
type: Heimdall.fg.HyenaDNAFg
args:
embedding_parameters:
type: Heimdall.embedding.FlexibleTypeEmbedding
constructor: from_pretrained
args:
embeddings: gene_embeddings
embedding_filepath: ${data_path}/pretrained_embeddings/hyenaDNA.pt
d_embedding: ${model.args.d_model}
frozen: true
Putting it all together#
from omegaconf import OmegaConf
with hydra.initialize(version_base=None, config_path="../Heimdall/config"):
config = hydra.compose(
config_name="config",
overrides=[
"+experiments=sctab_split1_all",
"fg=hyenadna",
"fe=zero",
"fc=geneformer",
],
)
OmegaConf.resolve(config)
Training the model#
from Heimdall.trainer import setup_trainer
def training_loop(config):
trainer = setup_trainer(config, cpu=config.trainer.cpu)
if trainer is not None:
trainer.fit()
from accelerate import notebook_launcher
args = (config,)
notebook_launcher(training_loop, args, num_processes=1)